Co-authored with Michael Tschannen and rollwag.
Large Language Models (LLMs) such as Anthropic’s Claude 3 have revolutionized applications, from chatbots to automated content generation. However, their increasing integration into digital services has also introduced novel security challenges. This blog explores the vulnerabilities of LLMs, common attack vectors, and strategies to mitigate these risks. Specifically, we look at a solution that generates code with an LLM and executes it in a corporate environment.
We take as a prominent example the option to interrogate CSV files by generating pandas code and create visualizations for it — a use case with high popularity. The pandasAI package already has 12.2k stars on Github at the moment of writing this blog.
In this context, we keep a fictitious use case in mind:
You work as a lead data scientist and ML Architect for the fitness and health tracker app ‘AnyFitness’ and want to allow your users to interrogate their fitness and health data. Your CTO is delighted, but health data is very sensitive so you need to really be sure that the privacy and security of the handled data is not compromised.
This means we think about a Business-to-Consumer (B2C) application where the data is already available in the cloud. You could also extend the thought exercise to a version where the users are allowed to upload the data themselves. However, this opens another threat vector through the instructions potentially contained within this data. More on this later.
What you find in this blog:
- A theoretical introduction to common attack vectors against LLMs and how to mitigate them
- A practical guideline on how to approach security risks when dealing with LLMs by using the threat modeling technique
- A case study on how to securely create an execution environment for LLM-generated code through AWS Lambda functions
- A summary of how AWS services can help you in this journey
1. TL;DR:
Large Language Models (LLMs) have revolutionized applications, but their integration into digital services has introduced novel security challenges. This blog explores common attack vectors against LLMs, such as insecure output handling, sensitive information disclosure, and excessive agency. It also provides practical guidance on threat modeling and mitigation strategies, including using ephemeral and isolated execution environments, limiting network connections, isolating languages and libraries, and implementing guardrails. Additionally, using AWS services like AWS Lambda, Amazon S3, and Amazon CloudWatch can streamline the secure execution of LLM-generated code.
2. Large Language Models (LLMs): A comer security perspective
Within this blog, we focus on using large language models (LLM) and exclude the process of creating them.
An LLM consists of two pieces: first, a small amount of code, and second, a large file containing the model weights. In essence, an LLM is not too much different from traditional software: It takes some input, runs code on it, respectively applies some transformation, and returns an output. As a result, many of the common security controls that are commonly used in software are applicable to using an LLM as well.
However, there are also differences. Traditional software is deterministic, which means that while we might be facing untrusted input, the output data is commonly under our control. With LLMs, a single execution steps is deterministic, but the combination of all steps that are taken within an inference process is not. With this, also the output data that is returned by an LLM is not fully deterministic, which can be translated to “not entirely under our control”. Additional controls are, therefore, required to safeguard an application. One example is the use of guardrails, which are available in Amazon Bedrock.
In the use-case presented in this article, we have an LLM generate source code and then run it. This is an excellent example of having a potentially untrusted output, which is used in subsequent steps in the process.
2.1 LLM-specific attack vectors
Common frameworks and knowledge bases that identify risks and threats in Generative AI applications include the OWASP Top 10 for Large Language Model Applications and MITRE ATLAS. The known risks, techniques, and tactics for attacks are still changing regularly; novel approaches are found in the various research that is currently conducted.
In this chapter, we discuss a few which are relevant to our use-case, based on the OWASP Top 10 framework, including a shortened definition.
- LLM02: Insecure Output Handling OWASP Definition: Insecure Output Handling refers specifically to insufficient validation, sanitization, and handling of the outputs generated by large language models before they are passed downstream to other components and systems. Since LLM-generated content can be controlled by prompt input, this behavior is similar to providing users indirect access to additional functionality. Why is it relevant? This is the most directly relevant risk when executing LLM-generated code, because the code is generated by an LLM and is thus not fully under our control.
- LLM06: Sensitive Information Disclosure OWASP Definition: LLM applications have the potential to reveal sensitive information, proprietary algorithms, or other confidential details through their output. This can result in unauthorized access to sensitive data, intellectual property, privacy violations, and other security breaches. Why is it relevant? The dynamically generated code could potentially contain or access sensitive information if not properly controlled.
- LLM08: Excessive Agency OWASP Definition: An LLM-based system is often granted a degree of agency by its developer — the ability to interface with other systems and undertake actions in response to a prompt. The decision over which functions to invoke may also be delegated to an LLM ‘agent’ to dynamically determine based on input prompt or LLM output. Excessive Agency is the vulnerability that enables damaging actions to be performed in response to unexpected/ambiguous outputs from an LLM (regardless of what is causing the LLM to malfunction; be it hallucination/confabulation, direct/indirect prompt injection, malicious plugin, poorly-engineered benign prompts, or just a poorly-performing model). Why is it relevant? Giving an LLM the ability to generate and execute code grants it a high degree of agency that needs to be carefully controlled.
- LLM09: Overreliance OWASP Definition: Overreliance can occur when an LLM produces erroneous information and provides it in an authoritative manner. While LLMs can produce creative and informative content, they can also generate content that is factually incorrect, inappropriate, or unsafe. This is referred to as hallucination or confabulation. When people or systems trust this information without oversight or confirmation, it can result in a security breach, misinformation, miscommunication, legal issues, and reputational damage. Why is it relevant? Blindly trusting and executing LLM-generated code without proper oversight/controls can lead to security vulnerabilities.
While other risks like prompt injection (LLM01) or training data poisoning (LLM03) could indirectly impact code generation, the below four risks are most directly relevant when it comes to actually executing dynamically generated LLM code.
2.2 General controls
Understanding techniques to compromise an LLM is crucial for both developers and users of LLMs. As mentioned earlier, an LLM shares a lot of the risks that we know from traditional software and, thus, well-known controls. Some of them include but are not limited to:
- Robust Access Controls Implement strict access controls to limit who can interact with the LLM and what kind of inputs they can provide. Make sure to follow a least-privilege principle throughout the whole pipeline, especially when additional elements, such as vector stores for RAG, are involved.
- Data Classification and Handling Perform a risk analysis and classification of any involved data. This includes training data, supporting data such as knowledge bases (for RAG), etc. Consider removing or sanitizing sensitive data from your workflows.
- Input Validation and Sanitization Use input validation to filter out obvious malicious inputs and input sanitization to neutralize potentially harmful elements within user inputs.
- Output Validation and Sanitization Validate and sanitize the data that was produced by the LLM before further processing it.
- Output Monitoring Employ real-time monitoring of the LLM’s outputs to detect and respond to suspicious activities promptly. Consider logging prompts and responses to allow anomaly detection.
- Verify: Is LLM-generated data needed, or is the data deterministic / known? Only use LLM-generated data when you need it. If information can be taken from a deterministic / verified source, use it from there. An example can be a user ID: If you know a user information in your code, use the proven source instead of a generated one.
- Regular Security Updates Continuously install patches and update security protocols and defenses to keep up with evolving techniques and tactics.
- Awareness and Training Educate developers and users about the potential risks and best practices for interacting with LLMs securely.
In this post, we deliberately focus on a technical perspective and omit equally important topics such as compliance and governance. Those should be considered for a holistic risk analysis, too.
As mentioned earlier, some controls we should consider are different from traditional software. Let’s dive into more details and a practical approach to them in the next chapter.
3. Threat modeling our LLM application
3.1 Threat Modeling Methodology
When dealing with potential security risks from executing LLM-generated code, it’s crucial to follow a structured approach for identifying and mitigating threats. One effective methodology for this is threat modeling, which we outline in this section before applying it to our “talk to my CSV” example.
On a high level, our use-case involves “executing code”. Let’s assume this code was developed by an engineering team — we would probably use mechanisms like code reviews, code scanners (Static Application Security Testing), vulnerability scans or penetration testing (incl. Dynamic Application Security Testing), etc. However, here we generate code dynamically, i.e., “on-the-fly”, and execute it. While we could use some of the mentioned mechanisms on the generated code, this step might add latency to the point that the usability of the solution is reduced and, in extreme cases, rejected by the users.
Instead, we think of the LLM-generated code as being “untrusted” and assume it’s potentially malicious. We put on the threat actor’s hat and think about where and how malicious code could be injected. Of course, we don’t want the LLM to produce such code, but having this mental model helps define the controls that are needed to safeguard the execution of this code.
There are various ways to approach risk modeling for an application. One of them is threat modeling, for example, using the STRIDE methodology. During threat modeling, we answer the following questions:
- What are we working on?
- What can go wrong?
- What are we going to do about it?
- Did we do a good job?
To answer the first question, we use a data flow diagram. This not only helps understanding how the system is intended to work, but also where and how data is accessed and used — including code generated by an LLM, as in our example.
Next, we think about “what could go wrong”, i.e., we are identifying the threats to our system. We use the data flow diagram to associate them with components, processes, or communication channels.
Once we have defined the threats, we will use a methodology inspired by insurance math (Actuarial science), as well as failure mode and effects analysis (FMEA) from engineering science. A risk can be looked upon as an event that has (1) a certain probability to happen and (2) an impact. The risk score can be calculated by generating the product of the two. Rating the different scores allows the categorization of risks using a risk matrix. The color coding can be used to imply how to cope with a fix (for example: red = must be mitigated, amber = can be accepted or mitigated, green = is automatically accepted). To prevent differences in the ratings, make sure to define a specific scale for both (e.g. “happens every x days/years” for the probability and a financial value for the impact).
Next, we plan mitigations for the threats we have identified in our applications and then re-assess our risks “after applying a mitigation”. These are the answers to “What are we going to do about it?”. Each mitigation either reduces the impact or probability of the risk and changes its position in the risk matrix. We do this until we reach a level where the residual risk associated with our application is acceptable.
The fourth and final question (“Did we do a good job?”) aims to improve both the quality of threat models and the velocity at which you are performing threat modeling over time. It is thus similar to retrospectives in agile software development processes.
In the next chapter, we execute these steps to assess the demo use-case we have introduced at the beginning of this article.
3.2 Creating the foundation
Let’s apply this and examine the example to interrogate a CSV file we upload in our application. We keep it AWS service agnostic and focus on the system itself.
First, lets look at a system overview (not yet a fully-fledged data flow diagram, we’ll do this in the next step):
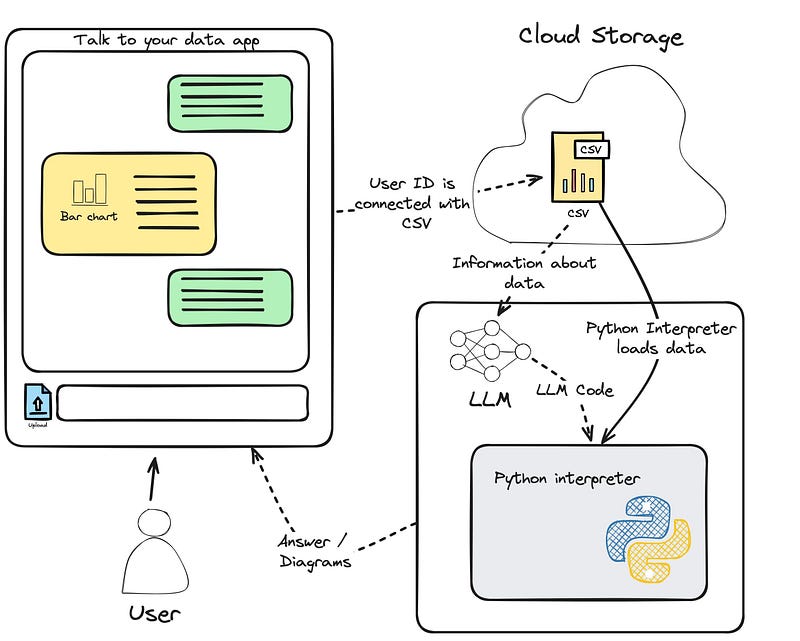
- The user uploads a .csv file, or the data is supplied by a backend system for the user interaction. You can imagine the .csv file as a mental placeholder for any data provisioning you might want to implement for your app.
- The LLM is supplied with the user query as well as some information about the data for which it should write code.
- Code and data are supplied to the Code interpreter (we place the Python symbol as a placeholder for other programming languages).
Let’s now create a data flow diagram for the application and start our threat modeling. Note that we have kept all steps minimal here for brevity. In the data flow diagram, we are specifically focusing on what data is passing through which part of the system:
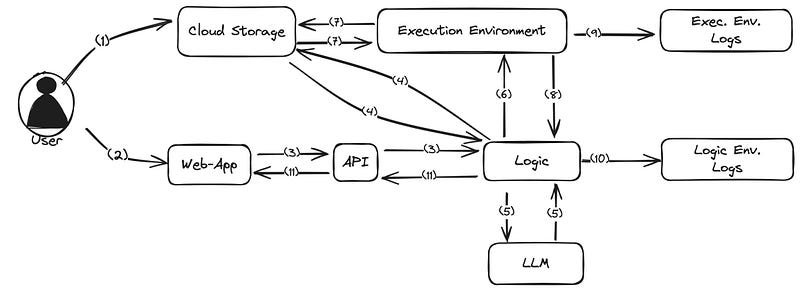
Here’s a description of the steps depicted in the diagram:
- The user uploads a CSV containing medical data to a cloud storage
- The user navigates to the web application
- The user sends a prompt on the client side, which is forwarded to logic by the API
- Logic downloads the CSV containing medical data from cloud storage to extract some basic information (e.g., number of rows, name of columns, etc.)
- Logic sends CSV information and user prompt to the LLM, which generates and returns Python code
- Logic sends the generated code and pointer to the CSV to the execution environment
- The execution environment downloads the CSV containing medical data from the cloud storage
- The execution environment executes the Python code and sends back the response to the logic
- The execution environment writes to the execution environment logs
- The logic environment writes to the logic environment logs
- Logic sends back the final response to the user
This diagram not only helps us better understand what data is involved, how it is used and transmitted, but also facilitates security-related conversations about the solution.
In the next step, we ask, “What can go wrong?” and we think about potential threats and risks.
3.3 Define threats
Let’s assume that we have an adversary trying to exploit our system through the prompt. Expecting the worst case is a good basis for this exercise. Try to “think like the threat actor we want to protect against.” They know the system is executing code that was generated on-the-fly; how could this potentially be abused?
This exercise leads to definitions of threats following a standardized pattern:
A [threat source] with [pre-requisites],can [threat action],which leads to [threat impact],negatively impacting [goal] of [impacted assets].
This format helps to be very specific about a threat, which supports the definition of countermeasures later in the process.
In this article, for the sake of brevity, we focus on some of the most relevant threats and use a formal definition for the first one only as an example (we are very happy for you to reach out and tell us more):
- (a) A threat actor with access to the public-facing application can inject malicious prompts that overwrite existing system prompts, which leads to the LLM generating malicious code and the execution environment executing it, for example, to mine cryptocurrencies or execute lateral movement, impacting the isolation of the execution environment.
- (b) A threat actor can trick the execution environment into loading a CSV from a different user and thus gain access to sensitive data.
- (c) The adversary gains continuous access (persistence), waiting for the next interaction to send out information.
- (d) A threat actor can bypass authentication and authorization and thus use the solution as an anonymous user.
- (e) A threat actor can trick the execution environment into writing malicious log data in the execution environment, which impacts the log data management software.
In the next step, we rate the impact and possibility of our threats and add them to a risk matrix. In a real-world scenario, we recommend pre-defining the different ratings for both impact and probability, which helps ensure a consistent rating of the risks. Also, note that you can use any size (for example, 5x5) that fits your requirements.
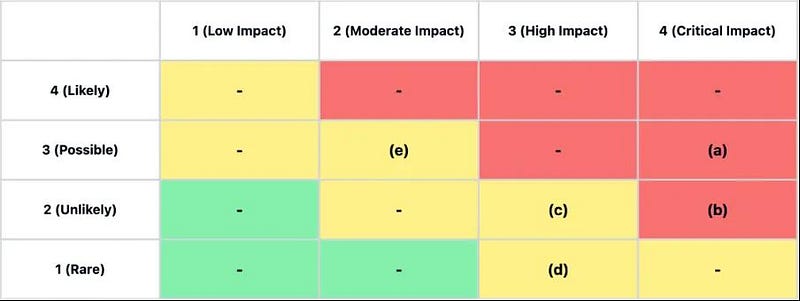
The color coding is often bound to the expected handling of the risk. An example is:
- Red: Not acceptable; must apply mitigations (which either reduce the probability or impact)
- Orange / Yellow: Can be accepted or mitigated
- Green: Are accepted by default
In a real-world scenario, also other actions on risks are common: Avoidance and transfer. For simplicity reasons, we focus on acceptance and mitigation/reduction.
With the defined classification in mind, let us re-examine the data flow diagram for our application, color-coding the threats in our data flow to examine which parts of the application are at risk when asking an LLM to generate code.
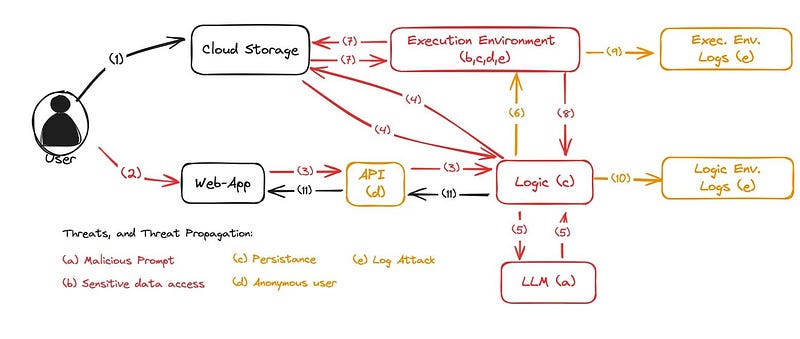
The data flow diagram for the generative AI application. Data flow is extended by the possible threat associated with it. Threat vectors are color-coded according to the severity outlined in the threat severity table above. It is clear that through one attack vector — the malicious prompt — the adversary can realize multiple attacks downstream of the LLM. Therefore, guardrails should be our first level of defense, fighting against attackers at the root of this problem.
Note that in common threat modeling exercises, color-coding a data flow diagram is optional. Use it when it helps you understand or explain the risk profile of your application.
3.4 Define countermeasures
Now that we have an overview of the risks for our use case let’s create a list of countermeasures that address the risks that have been collected. The risk matrix becomes handy here: Every countermeasure reduces a risk’s probability and/or its impact. With that, the risk changes its position in the matrix. We will continue this exercise until we are fine with the updated risk ratings.
(1) Ephemeral and isolated execution environment:
- Addresses: a, b, c, e
- Description: We want to have an ephemeral execution environment that is torn down after it fulfills its duty. Also, we need to ensure that the adversary is not able to stand up long-lasting tasks (e.g., mining crypto currencies on our system). Therefore, we need to limit the execution time to what we would expect as the time it takes our model to generate the code and the answer. An ephemeral infrastructure allows us to “accept that the environment breaks during execution”.
(2) No outgoing network connections:
- Addresses: a, c
- Description: To contain the reach of the code, we prohibit any outgoing network requests except for the ones needed to download a CSV file.
(3) Isolate language and libraries in the execution environment:
- Addresses: a, c
- Description: We design and build the execution environment in a “final” setup, i.e. prevent installing additional libraries. Also, we enforce the usage of the programming language that we define.
(4) Limit files that can be downloaded from the cloud storage:
- Addresses: b
- Description: We ensure that only legitimate files can be loaded by the execution environment. Since we know the user and their files in the “Logic” component, we can e.g. create a temporary download URL for a single file to the execution environment.
(5) Use Guardrails:
- Addresses: a, b, c, d, e
- Description: An effective measure and first layer of defense is setting up guardrails for incoming prompts as well as outgoing generated code.
(6) Sanitize logging of the execution environment:
- Addresses: e
- Description: We sanitize all logs written by the execution environment.
Once we have a final set of countermeasures and are fine with the residual risks, we can start implementing them.
4. Architecture on AWS
Let’s walk step-by-step through the defined countermeasures and how AWS services can be used to achieve them.
4.1 Ephemeral and isolated execution environment
AWS Lambda is an excellent choice for implementing this. It not only gives us the possibility to use an ephemeral infrastructure, but it also provides workload isolation of execution environments through Firecracker. Firecracker is a virtual machine monitor (VMM) that uses the Linux Kernel-based Virtual Machine (KVM) to create and manage microVMs, which provide enhanced security and workload isolation over traditional VMs while enabling the speed and resource efficiency of containers. At the time of this writing in preview, we could also change the architecture entirely to use the “Code interpretation” feature of Agents for Amazon Bedrock.
4.2 No outgoing network connections
We run AWS Lambda in a VPC and attach a Security Group to the Elastic Network Interface (ENI) to control any network connectivity. Assuming that CSV is stored in Amazon S3, we use a Gateway Endpoint to allow this access. In addition to that, we can optionally define Network Access Control Lists (NACL) to restrict network traffic further.
4.3 Isolate language and libraries in the execution environment
We can manage Python library dependencies either through directly including the required libraries in the Lambda deployment, or via AWS Lambda Layers. For both cases, to prevent that a threat actor download additional libraries, outgoing network access for the Lambda is blocked (see 4.2).
4.4 Limit files that can be downloaded from the cloud storage
We can use short-living, dynamically created Amazon S3 pre-signed URLs to download the CSV files from Amazon S3. In combination with a bucket policy, which only allows access to the bucket to the before-mentioned Gateway endpoint, we can additionally lock down our S3 bucket. You can find more information about this pattern in the AWS documentation.
4.5 Use Amazon Bedrock Guardrails
In Amazon Bedrock, we can use Guardrails to implement safeguards to the application requirements and responsible AI policies. In our example, we would for example use the “prompt attack” guardrail for prompts.
4.6 Sanitize logging of the execution environment
We can use the data protection policies feature of Amazon CloudWatch to sanitize our logs.
5. Conclusion
As Large Language Models (LLMs) continue to revolutionize various applications, it is crucial to address the novel security challenges they introduce. This blog has explored common attack vectors against LLMs, such as insecure output handling, sensitive information disclosure, and excessive agency. By following a structured threat modeling approach and implementing robust mitigation strategies, organizations can securely leverage the power of LLMs while minimizing risks.
Key strategies discussed include using ephemeral and isolated execution environments, limiting network connections, isolating languages and libraries, implementing guardrails, and sanitizing logs. Additionally, leveraging AWS services like AWS Lambda, Amazon S3, and Amazon CloudWatch can streamline the secure execution of LLM-generated code.
As the adoption of LLMs increases, developers and organizations should regularly review and update their security protocols to address new potential attack techniques. By prioritizing security and responsible AI practices, we can harness the full potential of LLMs while safeguarding against misuse and protecting sensitive data.
Explore the AWS services and best practices outlined in this blog to secure your LLM-powered applications. Stay informed about the latest developments in LLM security by following trusted cybersecurity resources and actively participating in community discussions.
Special mentions:
- Special thanks to Massimiliano Angelino, who created the first “talk to your CSV” implementation on Amazon Bedrock that inspired this blog, and to Luca Perrozzi for the valuable feedback and review.
Further reading: